Ingestion, retrieval, generation, and evaluation, a complete reference architecture.
 Saurabh Kumar19 Jun 2026
Saurabh Kumar19 Jun 2026
The archive

Ingestion, retrieval, generation, and evaluation, a complete reference architecture.
Saurabh Kumar19 Jun 2026

Canaries, gradual rollouts, and instant rollback, decoupling deploy from release.
Saurabh Kumar5 Jun 2026

A serverless, distributed SQL database, what it is, and where it fits today.
Saurabh Kumar21 May 2026

A back-of-envelope model for what idle headroom really costs you per year.
Saurabh Kumar7 May 2026

Queue-backed inference for large payloads and bursty traffic, scaling to zero between bursts.
Saurabh Kumar22 Apr 2026

Wiring CloudWatch, X-Ray, and OpenTelemetry into one coherent view.
Saurabh Kumar8 Apr 2026

Service-to-service auth and access policies without managing a mesh.
Saurabh Kumar20 Mar 2026

Schedule-driven cleanup of dev environments and orphaned resources, on autopilot.
Saurabh Kumar6 Mar 2026

SQS, SNS, EventBridge, Kinesis, MSK, an updated map of which fits which job.
Saurabh Kumar20 Feb 2026

Multi-step agents that call tools, what works, what fails, and how to keep costs sane.
Saurabh Kumar6 Feb 2026

The Framework is huge. Here’s the subset that earns its keep when you’re small.
Saurabh Kumar23 Jan 2026

An updated, prioritized list of cost levers, highest impact first.
Saurabh Kumar9 Jan 2026

Everything between “it works in the notebook” and a model serving real traffic.
Saurabh Kumar19 Dec 2025

Serverless SQL over your data lake, partitioning and formats that keep it fast and cheap.
Saurabh Kumar5 Dec 2025
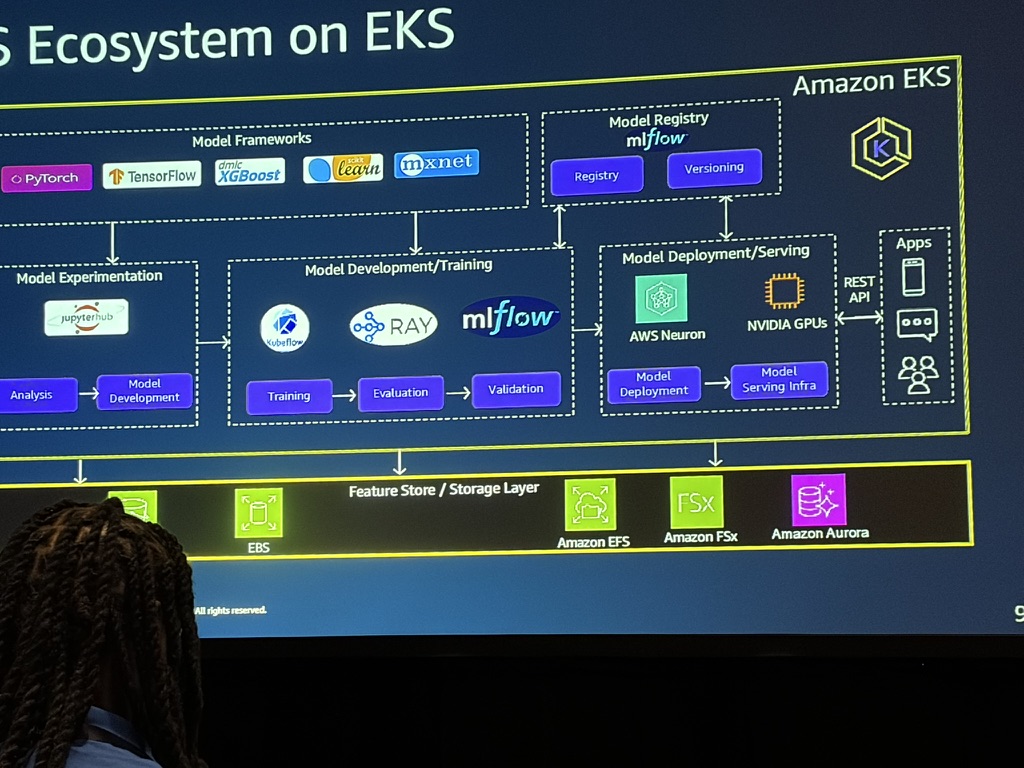
Field notes from Las Vegas: the keynotes, the standout announcements, and what I am taking back to production.
Saurabh Kumar2 Dec 2025

Long-running, fault-tolerant processes without managing servers or your own queue.
Saurabh Kumar20 Nov 2025

Cross-AZ, cross-region, and egress charges, the silent line items, mapped and tamed.
Saurabh Kumar6 Nov 2025

Routing easy requests to small models and hard ones to large, quality at a fraction of the cost.
Saurabh Kumar21 Oct 2025

Cache-aside, write-through, and the failure modes that bite under load.
Saurabh Kumar7 Oct 2025

Cutting through the findings firehose to the alerts that matter.
Saurabh Kumar22 Sep 2025

A 30-minute monthly ritual that catches waste before it compounds.
Saurabh Kumar8 Sep 2025

Tool use, action groups, and where managed agents fit versus rolling your own.
Saurabh Kumar20 Aug 2025

Building an evaluation harness so you can ship prompt and model changes with confidence.
Saurabh Kumar6 Aug 2025

At-least-once delivery means duplicates. Patterns to make handlers safe to retry.
Saurabh Kumar22 Jul 2025

Automatic tiering sounds free. Here’s the math on when it actually pays off.
Saurabh Kumar8 Jul 2025

From raw data in S3 to model-ready features, orchestrated and repeatable.
Saurabh Kumar20 Jun 2025

Federated, short-lived credentials for CI, delete those access keys for good.
Saurabh Kumar6 Jun 2025

Managed Kafka or Kinesis Data Streams? Throughput, ops burden, and cost compared.
Saurabh Kumar21 May 2025

How much to commit, for how long, and how to avoid over-committing into a corner.
Saurabh Kumar7 May 2025

Autoscaling, multi-model endpoints, and serverless inference, paying for what you use.
Saurabh Kumar22 Apr 2025

Active-active, active-passive, or just backups? Matching resilience to actual requirements.
Saurabh Kumar8 Apr 2025

Automatic rotation for database credentials and API keys, with zero downtime.
Saurabh Kumar21 Mar 2025

Bringing cost into the engineering loop without turning everyone into an accountant.
Saurabh Kumar7 Mar 2025

A decision framework for container compute on AWS that doesn’t cargo-cult big-company stacks.
Saurabh Kumar20 Feb 2025

Per-token pricing vs GPU instances, where the crossover point actually sits.
Saurabh Kumar6 Feb 2025

Golden paths, self-service, and the AWS building blocks that make a platform team possible.
Saurabh Kumar23 Jan 2025

A structured walk through every major lever, from compute commitments to storage tiering.
Saurabh Kumar9 Jan 2025

Data drift, model drift, and the metrics that tell you a model has quietly gone stale.
Saurabh Kumar19 Dec 2024

A decision framework for picking a database on AWS, by access pattern, not hype.
Saurabh Kumar6 Dec 2024

Two front doors for Lambda. Cost, features, and latency compared.
Saurabh Kumar21 Nov 2024

Turn last month’s surprise into next month’s forecast, with alerts before you blow the budget.
Saurabh Kumar7 Nov 2024

Ingest documents, chunk, embed, and query, a working RAG setup with managed pieces.
Saurabh Kumar22 Oct 2024

Point-to-point integrations with filtering and enrichment, minus the Lambda plumbing.
Saurabh Kumar8 Oct 2024

Block Public Access, policies, encryption, and the misconfigurations that cause breaches.
Saurabh Kumar20 Sep 2024

ARM-based instances are cheaper and faster for most workloads. Migrating is easier than you think.
Saurabh Kumar6 Sep 2024

When fine-tuning beats prompting, and how the Bedrock workflow actually looks.
Saurabh Kumar21 Aug 2024

Coordinate retries, timeouts, and human approval without writing your own state machine.
Saurabh Kumar7 Aug 2024

Cache keys, TTLs, and invalidation, squeezing hit rates out of not-quite-static content.
Saurabh Kumar23 Jul 2024

Without consistent tags, your cost reports are fiction. A tagging policy that sticks.
Saurabh Kumar8 Jul 2024

Storing and querying embeddings for semantic search and RAG, without a new database.
Saurabh Kumar20 Jun 2024

Remote state, locking, and the layout that prevents “who applied what” incidents.
Saurabh Kumar6 Jun 2024

Autoscaling Postgres/MySQL that scales to fractional capacity, and when it’s the wrong call.
Saurabh Kumar22 May 2024

Up to 90% off, if your workload tolerates interruption. Patterns that make it safe.
Saurabh Kumar8 May 2024

Package a model in a container, serve it from Lambda, pay only when it runs.
Saurabh Kumar23 Apr 2024

Subnets, routing, and endpoints, a pragmatic VPC layout you won’t outgrow next quarter.
Saurabh Kumar9 Apr 2024

Cold starts are real but often misunderstood. How to measure and when to care.
Saurabh Kumar22 Mar 2024

Log ingestion and custom metrics add up fast. A checklist to trim the bill.
Saurabh Kumar7 Mar 2024

SageMaker Feature Store solves a real problem, but only past a certain scale.
Saurabh Kumar21 Feb 2024

Allow, deny, boundaries, SCPs, the order AWS evaluates them, and why your policy isn’t working.
Saurabh Kumar6 Feb 2024

A gentler path into single-table modeling, with access patterns front and center.
Saurabh Kumar24 Jan 2024

NAT Gateways quietly bleed money on data processing. Here’s how to find and fix it.
Saurabh Kumar9 Jan 2024

When you don’t need a real-time endpoint, batch transform is cheaper and simpler.
Saurabh Kumar19 Dec 2023

Blue/green deployments on ECS that roll back automatically when health checks fail.
Saurabh Kumar7 Dec 2023

Account structure, SCPs, and guardrails you’ll wish you had from day one.
Saurabh Kumar23 Nov 2023

How commitment-based discounts actually work, and a buying strategy that hedges risk.
Saurabh Kumar8 Nov 2023

Three messaging services, three jobs. A decision guide with real examples.
Saurabh Kumar20 Oct 2023

A first SageMaker project that won’t surprise you with a four-figure bill.
Saurabh Kumar6 Oct 2023

Standard, IA, One Zone, Glacier, a plain-English map of when each one saves you money.
Saurabh Kumar21 Sep 2023

A repeatable process for finding over-provisioned instances and acting on it without breaking prod.
Saurabh Kumar7 Sep 2023